
Быстро нарисовать пейзаж ночного города акварелью.
Городские пейзажи – это то что окружает нас постоянно, но мы часто не замечаем этих красивых улочек, парков и видов из окна, пока нас не заставляют увидеть эту красоту художники.
Нам необходимо для рисования пейзажа:
- Акварель
- Акварельная бумага
- Кисти
- Палитра
- Белая гуашь
- Старая зубная щетка
- Вода
Сначала, создадим оттенки цветов на палитре, которые нам понадобится для создания ночного, звездного неба, смешиваем фиолетовый, синий, розовый и красный, для ночных домов и окон смешиваем желтые и оранжевые оттенки.
Наносим несколько штрихов фиолетового цвета на бумагу, даем краске растечься по листу, таким способом закрашиваем верхнюю часть листа
Добавляем синего и малинового оттенка, и видим, что цвета плавно соединяются между собой, обратите внимание, что лист не намокает, но краска в большом объеме смешана с водой смешана с водой это нужно чтобы цвета могли красиво соединяться между собой. Закрашиваем верхнюю большую часть листа разными оттенками фиолетового, синего и других темных и холодных оттенков, но заканчивается небо красными цветами.
Переворачиваем лист, чтобы небо было внизу и вверх раскрашиваем желтым и оранжевым цветом, позволяем малиновому и желтому соединиться
Переворачиваем рисунок назад, добавляем для контраста фиолетовый и темно-красный цвет к небу. Даем рисунку полностью высохнуть, а затем карандашом рисуем множество зданий с разной высотой и расположением окон.
Раскрашиваем здания черным, окна оставляем не тронутыми, звезды на этом рисунке лучше рисовать белой гуашью, также можно с помощью старой зубной щетки можно разбрызгать белую краску по небу.
Дизеринг
Сохранение цветов – вот на что создателям пиксель арт действительно нужно обратить внимание. Ещё один способ получить больше теней без использования большего количества цветов называется «дизеринг»
Также как в традиционной живописи используется «штриховка» и «перекрестная штриховка», то есть вы, в прямом смысле, получаете что-то среднее из двух цветов.
Вот простой пример того, как, посредством дизеринга, из двух цветов можно создать четыре варианта шейдинга.
Продвинутый пример
Сравните картинку сверху (созданную с помощью градиента в фотошопе) с картинкой, созданной всего из трёх цветов, используя дизеринг. Учтите, что различные узоры могут быть использованы для создания «смежных цветов». Вам будет проще понять принцип, если вы сами создадите несколько узоров.
Применение
Дизеринг может придать вашему спрайту тот прекрасный ретро-вид, так как множество первых видео игр очень активно использовали данную технику ввиду малого количества доступных палитр цветов (если вы хотите увидеть множество примеров дизеринга – посмотрите на игры, разработанные для Sega Genesis). Я сам не очень часто использую этот способ, но для обучающих целей, я покажу как это можно применить на нашем спрайте.
Вы можете использовать дизеринг сколько вашей душе угодно, но стоит отметить, что лишь несколько людей применяют его действительно удачно.
Как работает GauGan 2
Компания Nvidia выпустила свою нейронную сеть, которая умеет рисовать по подсказкам. Она представлена на сайте GauGan2. Перед вами располагается холст, где вы должны давать подсказки нейросети. Перед использованием поставьте галочку на пункте Check This Box внизу страницы, иначе работать не будет
Теперь начните рисовать с помощью кисти что-нибудь примитивное: домик, облака, звёзды – неважно. Когда закончите, нажмите вверху стрелочку вправо, чтобы нейросеть показала вам, на что это похоже
У вас будет большой арсенал инструментов: пипетка для копирования цвета, кисти, карандаш, ластик, готовые элементы. Используйте их для наброска, а GauGan сгенерирует для вас изображение, которые более походит на реальные объекты. Ему нужно подсказывать темами из меню в левой колонке. И самое интересное, что сайт не берёт настоящие изображения из интернета, а рисует свои. Впрочем, иногда генератор филонит: вместо непонятно для него нарисованного предмета показывает изображения ночного неба или космоса. Есть и строка для ввода текста, по которому генерируются рисунки.
И самое интересное, что сайт не берёт настоящие изображения из интернета, а рисует свои. Впрочем, иногда генератор филонит: вместо непонятно для него нарисованного предмета показывает изображения ночного неба или космоса. Есть и строка для ввода текста, по которому генерируются рисунки.
Что делать, если Youtube заблокируют в России?
Построение сети
Имея в наборе готовые строительные блоки, можно собирать различные нейронные сети. Для классификации изображений чаще всего используется следующуя последовательность блоков: хn-MAXPOOL]хm-FC. Так, например, чтобы достичь точности около 99.5% для распознавания изображений цифр, можно использовать вот такую сеть: CONV16C3-RELU-CONV16C3-RELU-MAXPOOL-CONV32C3-RELU-CONV32C3-RELU-MAXPOOL-FC128-FC10. Запись CONV16C3 означает, что в свёрточном слое используется 16 фильтров размером 3х3, с нулевым дополнением (P=0) и единичным шагом (S=1), а запись FC128 означает, что используется полносвязный слой из 128 нейронов. Ещё одним примером известной архитектуры свёрточных сетей является сеть VGG19: она содержит 24 слоя, среди которых 16 свёрточных и 3 полносвязных слоя.
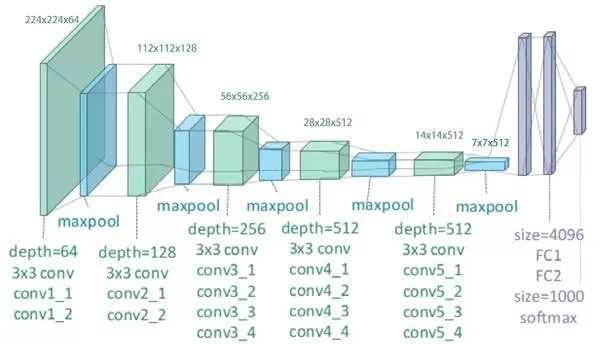
Архитектура сети VGG19
Создание набора обучающих данных
Нейронная сеть на Python, о которой мы говорили в части 12, импортирует обучающие выборки из файла Excel. Обучающие данные, которые я буду использовать для этого примера, организованы следующим образом:
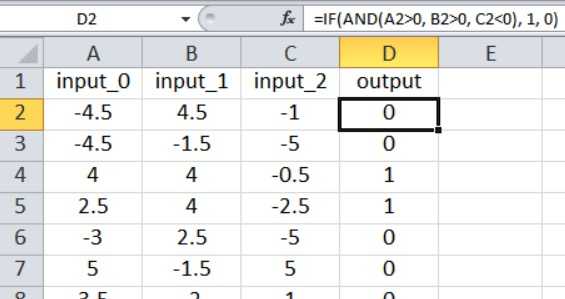 Рисунок 4 – Обучающие данные в таблице Excel
Рисунок 4 – Обучающие данные в таблице Excel
Наш текущий код для перцептрона ограничен одним выходным узлом, поэтому всё, что мы можем сделать, – это выполнить классификацию типа «истина/ложь». Входные значения – это случайные числа от –5 до +5, сгенерированные по формуле Excel:
Как показано на скриншоте, результат рассчитывается следующим образом:
Таким образом, выходное значение равно , только если больше нуля, больше нуля, а меньше нуля. В противном случае выходное значение равно .









Это математическая связь вход-выход, которую перцептрон должен извлечь из обучающих данных. Вы можете создать столько выборок, сколько захотите. Для такой простой задачи, как эта, вы можете достичь очень высокой точности классификации с 5000 выборками и одной эпохой.
Layers
Слои в нейронной сети очень важны, поскольку мы видели ранее, что искусственная нейронная сеть состоит из трех слоев: входной, скрытый и выходной. Входной слой состоит из функций и значений, которые необходимо проанализировать внутри нейронной сети. По сути, это слой, который считывает наши входные данные в искусственную нейронную сеть.
Скрытый слой — это слой, где вся магия происходит, когда все входные нейроны передают функции скрытому слою с весом и смещением, каждый нейрон внутри скрытого слоя суммирует все взвешенные характеристики со всех входных слоев и примените функцию активации, чтобы сохранить значения от 0 до 1 для облегчения обучения. Здесь нам нужно выбрать количество нейронов в каждом слое вручную, и оно должно быть лучшим значением для сети.
Здесь настоящие лица, принимающие решения, — это веса между каждым слоем, которые в конечном итоге передают значение от 0 до 1 на выходной уровень
До этого мы видели важность каждого уровня слоев в искусственной нейронной сети. В TensorFlow есть много типов слоев, но мы будем часто использовать Dense
Это полностью связанный слой, в котором каждый вход функции будет каким-то образом связан с результатом.
Что представляют свёрточные нейронные сети
В отличие от сетей прямого распространения, которые работают с данными в виде векторов, свёрточные сети работают с изображениями в виде тензоров. Тензоры — это 3D массивы чисел, или, проще говоря, массивы матриц чисел.

Представление изображений
Изображения в компьютере представляются в виде пикселей, а каждый пиксель – это значения интенсивности соответствующих каналов. При этом интенсивность каждого из каналов описывается целым числом от 0 до 255. Чаще всего используются цветные изображения, которые состоят из RGB пикселей – пикселей, содержащих яркости по трём каналам: красному, зелёному и синему. Различные комбинации этих цветов позволяют создать любой из цветов всего спектра. Именно поэтому вполне логично использовать именно тензоры для представления изображений: каждая матрица тензора отвечает за интенсивность своего канала, а совокупность всех матриц описывает всё изображение.
Изображение цифры из датасета MNIST
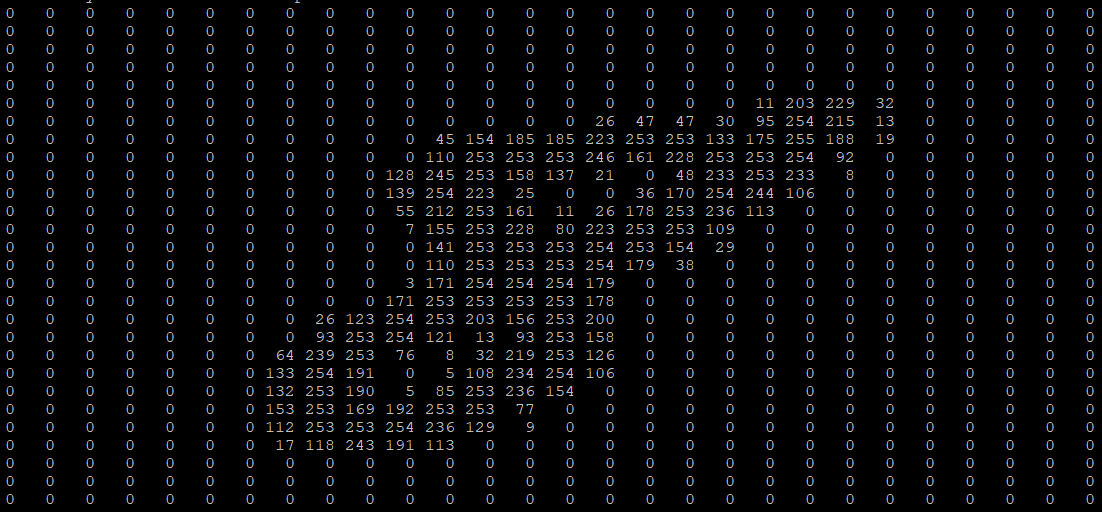
Эта же цифра в компьютере
Инструменты Paint
«Паинт» обладает довольно ограниченным набором возможностей, однако с ними все равно стоит ознакомиться, прежде чем приступать к рисованию.
После запуска программы все доступные инструменты вы найдете на верхней панели. Всего вам доступны две вкладки: «Главная» и «Вид». В главной вкладке есть такие группы инструментов:
- «Буфер обмена» — содержит стандартные возможности вставить, вырезать и копировать изображение или его фрагмент.
- «Изображение» — позволяет выделить, повернуть и поменять размер рисунка или фотографии.
- «Инструменты» — содержит небольшой набор кистей и набор стандартных инструментов для рисования.
- «Фигуры» — дает возможность добавить фигуру, изменить цвет ее заливки и контура, выбрать толщину линии.
- «Цвета» — позволяет выбрать цвет линий и заливки.
Во вкладке «Вид» вы имеете возможность приблизить или отдалить изображение, включить линейку, сетку и отображение строки состояния, а также развернуть рисунок во весь экран.
Как нарисовать замок в Paint
Дом или простой человечек — это не единственное, что легко и красиво можно нарисовать в «Паинт». Например, в этой программе вы можете изобразить целый замок. Для этого нарисуйте с помощью фигур три прямоугольника. Центральная фигура должна быть ниже остальных.
Добавьте сверху каждого прямоугольника по три зубца. Для этого можно использовать фигуру «Прямоугольник» или нарисовать зубцы карандашом. Таким образом у вас получится три башенки. На высоких башнях рисуем окна с помощью скругленных прямоугольников. На центральной башне добавляем ворота, и проводим на них несколько линий.
По бокам можно дорисовать зубчатые стены и дорогу перед воротами, используя фигуру «Линия». Закончив рисовать контур, используйте заливку, чтобы быстро и легко покрасить рисунок.
О чём статья
Статья освещает следующие аспекты:
- моментальное исполнение (англ. Eager Execution) — использование библиотеки TensorFlow, которая позволяет выполнять операции незамедлительно, без построения графов. Тут можно узнать больше о моментальном исполнении, а увидеть в действии можно тут;
- работа с functional API для определения модели — вы будете использовать подмножество моделей, чтобы получить доступ к важным промежуточным функциям активации с помощью functional API;
- использование карт признаков подготовленной модели;
- создание собственных циклов обучения — вы научитесь минимизировать заданные потери входных параметров.
Выполняя перенос стиля, вы проделаете следующие шаги:
- Визуализация данных.
- Базовая предварительная обработка/подготовка данных.
- Настройка функций потери.
- Создание модели.
- Оптимизация функции потери.
Примечание Этот пост рассчитан на тех, кто уже знаком с базовыми концепциями машинного обучения. Чтобы извлечь максимум из этой статьи, рекомендуется сначала ознакомиться со следующими материалами:
- https://tproger.ru/translations/6-step-for-building-machine-learning-projects/
- https://tproger.ru/translations/math-for-ai-linear-algebra/
- https://tproger.ru/video/machine-learning-2014/?autoplay=1
- https://tproger.ru/digest/learning-neuroweb-all-for-begin/
- https://tproger.ru/experts/required-ml-skills/
Красочная картина гуашью
С карандашами разобрались, теперь будем рисовать гуашью. Если вы смогли выполнить предыдущий вариант, то с этим рисунком у вас не возникнет сложностей. На сайте megamaster.info вы можете ознакомиться с уроками, чтобы облегчить задачу. Для этой работы нам потребуется альбом, простой карандаш, гуашь, кисти и ёмкость с водой.
Подготовив всё необходимое, приступаем к созданию шедевра:
- Простым карандашом в левом нижнем углу делаем набросок берега и выделяем небольшой мостик. Поднимаемся и в правой стороне изображаем остров с несколькими силуэтами деревьев. Выше середины ближе к левой части листа выводим ещё один островок и рисуем на нём множество деревьев. Дополняем это место двумя возвышенностями.
- Как сделать набросок этого пейзажа карандашом разобрались, теперь будем работать красками. На кисть набираем белую краску этим цветом закрываем верхний участок до половины листа. Вымываем кисть и жёлтой гуашью изображаем в небе солнце. В жёлтый цвет добавляем коричневый и закрашиваем периметр вокруг солнца. Добавляем сюда же фиолетовый и закрашиваем верхние углы.
- Пока все цвета не высохли выбеливаем их белым цветом, чтобы получить более плавный переход. В смесь всех предыдущих красок добавляем тёмно-зелёную гуашь и результатом начинаем выводить крону растений.
- Теперь смешиваем коричневый материал с зелёным и закрашиваем все островки на среднем и заднем фоне. На берегу с правой части листа жёлтым уточняем тропинку. Края затемняем смесью коричневого с зелёным.
- Покрываем до нижнего берега белилами. Жёлтым материалом показываем на поверхности воды солнечное отражение. В жёлтую добавляем оранжевую гуашь и наводим контур солнечного отражения. Добавим немного коричневого по двум бокам. Кистью смешиваем эти цвета, чтобы получить плавный переход оттенков.
- В предыдущий оттенок добавляем фиолетовую краску и закрашиваем правую и левую сторону озера. Зелёным, которыми рисовали деревья, на поверхности озера изображаем тени исходящие от растений. Бежевой краской с добавлением небольшого количества розового обрабатываем светлые места на кронах деревьев с правой стороны.
- Этим же тоном прорабатываем детали и на левой стороне. Добавляем немного зелёного и детально уточняем световые участки на листьях. Теперь нансоим белила в зелёную гуашь и прорабатываем детали на поверхности воды. Чистой, белой краской осветляем солнечное отражение и на изображённые кувшинки дорисовываем цветочки.
- Далее, смешиваем коричневую с зелёной краской. Полученным оттенком показываем траву на берегу в нижнем левом углу. Материалом серого цвета делаем набросок мостика. Осветляем его белилами и более тёмным показываем объём досок. Далее прорисовываем каждую доску на мосте.
- Тёмно-зелёную краску смешиваем с небольшим количеством чёрной детально прорисовываем тут несколько кустиков травы. Осветляем белилами и изображаем траву более светлого тона. Жёлтой осветляем края травинок и на этом этапе рисование завершается.
Этот творческий процесс о том, как нарисовать пейзаж гуашью, немного сложней предыдущих, но придерживаясь нашего инструктажа вы с ним легко справитесь. После создания такого шедевра сами удивитесь, как на самом деле всё легко рисовать.










Краски в осеннем пейзаже
В начале осени деревья и кустарники меняют цвет, в лесу парк становится красивым. И такую картину можно сразу раскрасить красками.
В предлагаемом варианте используется простая техника рисования:
- Линия горизонта отмечается синей краской, она не должна быть прямой.
- Небо окрашено в синий цвет: сверху оно темнее, ближе к горизонту светлее. Более светлый оттенок достигается за счет смешивания белого и синего. Мазки кистью выполняются в одном направлении.
- Танк нарисован в зеркальном отражении неба. Внизу более темный оттенок, чем горизонтальная линия.
- Облака. Техника, как легко нарисовать воздушную и прозрачную фигуру: средней кистью белой краской короткими мазками нарисуйте облако. Нельзя сначала проследить путь, а потом закрасить его.
- Прибрежная часть рисуется от горизонта. Как раз не дойдя до левой стороны листа, щетка останавливается. Другая часть побережья уходит немного влево, показывая бесконечность горизонта. Сначала берется краска темно-коричневого тона. Так, кое-где штрихи выполнены светло-коричневым цветом, а в конце — желтым.
- Стволы деревьев тоже рисуют темно-коричневой краской, но кисть берется тонкой. Березы нарисованы белым цветом с черными штрихами.
- Листья не следует прорисовывать подробно. Вам просто нужно обозначить корону в три слоя — желтый, оранжевый и зеленый.
- Для правдоподобия вы можете показать, как деревья отражаются в воде. Тона подобраны так же, как красили деревья. Отражение размытое и не темное.
Таким способом можно рисовать не только акварелью, но и масляными красками.
Плюсы и минусы классификатора ближайших соседей
Стоит рассмотреть некоторые преимущества и недостатки классификатора ближайших соседей. Ясно, что одним из преимуществ является то, что его очень просто реализовать и понять. Кроме того, классификатор не требует времени для обучения, так как все, что требуется, — это хранить и, возможно, индексировать обучающие данные. Однако мы расплачиваемся за эту экономию вычислительных затрат во время использования, поскольку классификация тестового примера требует сравнения с каждым отдельным обучающим примером. Это обратная сторона, так как на практике мы часто заботимся об эффективности времени использования гораздо больше, чем об эффективности во время обучения. На самом деле, глубокие нейронные сети, которые мы будем рассматривать позже в этом курсе, переносят этот компромисс в другую крайность: они очень дороги для обучения, но как только обучение закончено, очень дешево классифицировать новый тестовый пример. Этот режим работы гораздо более желателен на практике.
Кроме того, вычислительная сложность классификатора ближайшего соседа является активной областью исследований, и существует несколько приближенных алгоритмов и библиотек (Approximate Nearest Neighbor/ANN), которые могут ускорить поиск ближайшего соседа в наборе данных (например, FLANN). Эти алгоритмы позволяют компенсировать корректность поиска ближайшего соседа его размерно/временной сложностью во время поиска и обычно полагаются на стадию предварительной обработки/индексирования, которая включает в себя построение kdtree или запуск алгоритма k-means.
Классификатор ближайших соседей иногда может быть хорошим выбором в некоторых случаях (особенно если данные являются низкоразмерными), но он редко подходит для использования в практических ситуациях классификации изображений. Одна из проблем заключается в том, что изображения являются многомерными объектами (т. е. они часто содержат много пикселей), а расстояния в многомерных пространствах могут быть очень противоречивыми. Изображение ниже иллюстрирует тот момент, что пиксельные сходства L2, которые мы разработали выше, очень отличаются от перцептивных сходств:
 Пиксельные расстояния на основе многомерных данных (и особенно изображений) могут быть очень неинтуитивными. Исходное изображение (слева) и три других изображения рядом с ним, которые равноудалены от него на расстояние L2 пикселей. Очевидно, что пиксельное расстояние вовсе не соответствует перцептивному или семантическому сходству.
Пиксельные расстояния на основе многомерных данных (и особенно изображений) могут быть очень неинтуитивными. Исходное изображение (слева) и три других изображения рядом с ним, которые равноудалены от него на расстояние L2 пикселей. Очевидно, что пиксельное расстояние вовсе не соответствует перцептивному или семантическому сходству.
Вот еще одна визуализация, которая убедит вас в том, что использование различий пикселей для сравнения изображений является недостаточным. Мы можем использовать технику визуализации, называемую t-SNE, чтобы взять изображения CIFAR-10 и встроить их в два измерения так, чтобы их (локальные) попарные расстояния лучше всего сохранялись. В этой визуализации изображения, которые показаны рядом, считаются очень близкими в соответствии с пиксельным расстоянием L2, которое мы разработали выше:
Изображения CIFAR-10, встроенные в два измерения с помощью t-SNE. Изображения, находящиеся рядом на этом изображении, считаются близкими на основе расстояния L2
Обратите внимание на сильный эффект фоновых, а не семантических различий классов. Нажмите здесь, чтобы получить более полную версию этой визуализации
В частности, обратите внимание, что изображения, которые находятся рядом друг с другом, гораздо больше зависят от общего цветового распределения изображений или типа фона, чем от их семантической идентичности. Например, собаку можно увидеть совсем рядом с лягушкой, так как обе они находятся на белом фоне
В идеале мы хотели бы, чтобы изображения всех 10 классов образовывали свои собственные кластеры, так чтобы изображения одного и того же класса находились рядом друг с другом независимо от несущественных характеристик и вариаций (таких как фон). Однако, чтобы получить это свойство, нам придется выйти за рамки простых характеристик пикселей.
Теория трансферного обучения
Использование трансферного обучения имеет несколько важных концепций. Чтобы понять реализацию, нам нужно рассмотреть, как выглядит предварительно обученная модель и как ее можно настроить для ваших нужд.
Выбрать модель для трансферного обучения можно двумя способами. Можно создать модель с нуля для собственных нужд, сохранить параметры и структуру модели, а затем повторно использовать ее позже.
Второй способ реализовать трансферное обучение – просто взять уже существующую модель и повторно использовать ее, настраивая при этом ее параметры и гиперпараметры. В этом случае мы будем использовать предварительно обученную модель и модифицировать ее. После того, как вы решили, какой подход вы хотите использовать, выберите модель (если вы используете предварительно обученную модель).
В PyTorch можно использовать множество предварительно обученных моделей. Некоторые из CNN включают:
- AlexNet;
- CaffeResNet;
- Inception;
- Серия ResNet;
- Серия VGG.
Эти предварительно обученные модели доступны через API PyTorch, и после получения инструкций PyTorch загрузит их спецификации на ваш компьютер. Конкретная модель, которую мы собираемся использовать, – это ResNet34, часть серии Resnet.
Модель Resnet была разработана и обучена на наборе данных ImageNet, а также на наборе данных CIFAR-10. Таким образом, он оптимизирован для задач визуального распознавания и показал заметное улучшение по сравнению с серией VGG, поэтому мы будем его использовать.
Однако существуют и другие предварительно обученные модели, и вы можете поэкспериментировать с ними, чтобы увидеть, как они сравниваются.
Как объясняется в документации PyTorch по трансферному обучению, существует два основных способа использования: точная настройка или использование CNN в качестве средства извлечения фиксированных функций.
При тонкой настройке CNN вы используете параметры, которые имеет предварительно обученная сеть, вместо их случайной инициализации, а затем тренируетесь как обычно. Напротив, подход экстрактора признаков означает, что вы будете поддерживать все параметры CNN, за исключением тех, которые находятся на последних нескольких уровнях, которые будут инициализированы случайным образом и обучены как обычно.









Точная настройка модели важна, потому что, хотя модель была предварительно обучена другой (хотя, надеюсь, схожей) задаче. Плотно связанных параметров, с которыми поставляется предварительно обученная модель, вероятно, будет недостаточно, поэтому вы, вероятно, захотите переобучить последние несколько слоев сети.
Напротив, поскольку первые несколько слоев сети – это просто слои выделения признаков, и они будут работать аналогично с похожими изображениями, их можно оставить как есть. Следовательно, если набор данных небольшой и похожий, единственное обучение, которое необходимо выполнить, – это обучить нескольких последних слоев. Чем больше и сложнее будет набор данных, тем больше потребуется переобучения модели.
Помните, что трансферное обучение работает лучше всего, когда набор данных, который вы используете, меньше, чем исходная предварительно обученная модель, и похож на изображения, подаваемые в предварительно обученную модель.
Работа с моделями обучения передачи в Pytorch означает выбор слоев, которые нужно заморозить и разморозить. Замораживание модели означает указание PyTorch сохранить параметры в указанных вами слоях. Размораживание модели означает сообщение PyTorch о том, что вы хотите, чтобы указанные вами слои были доступны для обучения.
После того, как вы завершили обучение выбранных вами слоев предварительно обученной модели, вы, вероятно, захотите сохранить параметры для использования в будущем. Несмотря на то, что использование предварительно обученных моделей происходит быстрее, чем обучение модели с нуля, обучение по-прежнему требует времени, поэтому вы захотите скопировать лучшие параметры модели.
Итоги
Мы научились использовать технологию переноса обучения (transfer learning) для применения предварительно обученных сетей к новым типам задач. Краткая схема переноса обучения для задач компьютерного зрения:
- Выбрать предварительно обученную нейронной сети и взять от нее только сверточную часть, удалив полносвязную. В Keras нужно указать параметр при создании сети.
- Создать составную сеть на основе предварительно обученной сети и нового классификатора, который создается для нашей задачи. Предварительно обученную сеть можно добавить в составную сеть таким же образом, как добавляем отдельные слои.
- Обучить составную сеть на новом наборе данных. Обучать нужно только веса добавленного в сеть классификатора, предварительно обученная сверточная часть должна быть «заморожена».
P.S. Как всегда, не забудьте сохранить обученную сеть для последующего использования!
Заключение
- Мы ввели задачу классификации изображений, в которой нам дается набор изображений, которые все помечены одной категорией. Затем нас просят предсказать эти категории для нового набора тестовых изображений и измерить точность предсказаний.
- Мы ввели простой классификатор, называемый классификатором ближайших соседей (Nearest Neighbor classifier). Мы видели, что существует множество гиперпараметров (таких как значение k или тип расстояния, используемого для сравнения примеров), которые связаны с этим классификатором, и не нашли очевидного способа их выбора.
- Мы увидели, что правильный способ установить эти гиперпараметры — разделить ваш обучающие набор на два: тренировочный набор и поддельный набор тестов, который называется проверочным набором. Мы пробуем различные значения гиперпараметров и сохраняем значения, которые приводят к лучшей производительности в наборе проверки.
- Если существует проблема отсутствия обучающих данных, мы обсудили процедуру, называемую перекрестной проверкой, которая может помочь уменьшить шум при оценке того, какие гиперпараметры работают лучше всего.
- Как только лучшие гиперпараметры найдены, мы фиксируем их и выполняем единственную оценку на актуальном наборе тестов.
- Мы видели, что ближайший сосед может дать нам около 40% точности на CIFAR-10. Он прост в реализации, но требует, чтобы мы хранили весь учебный набор, и это затратно, для оценки тестового изображения.
- Наконец, мы увидели, что использование расстояний L1 или L2 для простых характеристик пикселей не является адекватным, поскольку расстояния коррелируют более сильно с фоном и цветовыми распределениями изображений, чем с их семантическим содержанием.
В следующих частях мы приступим к решению этих проблем и в конечном итоге придем к решениям, которые дают точность 90%, позволяют полностью отказаться от обучающего набора после завершения обучения, и способны оценить тестовое изображение менее чем за миллисекунду.



